APRIL实验室2篇论文被NeurIPS 2021录用

9月29日凌晨,全球人工智能顶会 NeurIPS 2021 官方发布了今年的论文接收列表。APRIL实验室博士生张江宁、硕士生李梓彰的2篇论文被录用,恭喜他们实现新的突破。
据大会官方统计,今年 NeurIPS 共有 9122 篇有效论文投稿,总接收率 26%。作为当前全球最负盛名的 AI 学术会议,NeurIPS 是每年学界的重要事件。它的全称是 Neural Information Processing Systems,神经信息处理系统大会,通常在每年 12 月由 NeurIPS 基金会主办。大会讨论的内容包含深度学习、计算机视觉、大规模机器学习、学习理论、优化、稀疏理论等众多细分领域,其论文集代表了机器学习和人工智能领域最新的研究进展。中国计算机学会将其列为A类会议,是大家公认级别最高的人工智能会议之一。

下面将和大家分享张江宁和李梓彰2位同学的论文。
01 Analogous to Evolutionary Algorithm: Designing a Unified Sequence Model (类比进化算法:设计统一的序列模型)
论文链接:https://arxiv.org/pdf/2105.15089.pdf
代码链接:https://github.com/TencentYoutuResearch/BaseArchitecture-EAT
背景介绍:
自从ViT提出之后,许多基于Transformer的改进工作在图像分类中取得了不错的结果。然而,很少有工作对Transformer结构的有效性进行研究并解释,同时也尚未有工作采用统一的思想探究如何使用一个模型来解决多模态问题。我们首次通过进化算法的角度对Transformer结构进行解释,并提出了一个统一的序列模型范式去解决多模态问题。我们的贡献有以下几点:
1. 理论上,我们通过类比进化算法(EA)来解释Vision Transformer(TR)的合理性,并推导出它们具有一致的数学表示。
2. 方法上,类比EA中的动态局部种群概念,我们对ViT模型进行改进,设计了一个效率更高、效果更好的EAT模型,并提出了Task-related Head模块来更灵活、更优雅地处理多个任务。
3. 框架上,我们引入了空间填充曲线(SFC)模块作为二维图像数据和一维序列数据之间的桥梁,使得仅用一个统一模型解决多模态任务的统一范式成为可能,同时将网络架构设计和数据结构独立开来。
4. 分类和多模态实验证明了我们方法的优越性和灵活性。
EA解释:
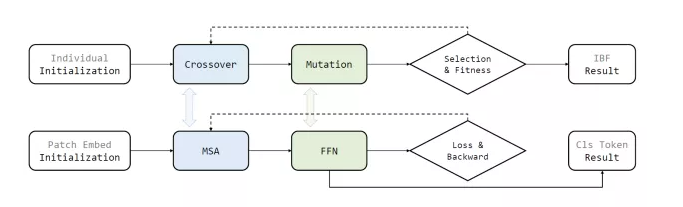
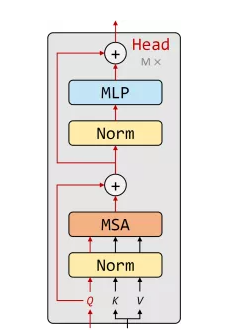
我们通过类比EA中的交叉算子、变异算子、种群继承、最优得分个体输出对Transformer中的MSA、FFN、Skip、Cls Token进行解释,并在数学上推导出其具有一致的公式表达,如图1所示:
EAT模型:
基于ViT,我们设计了改进的EAT模型如图2所示:
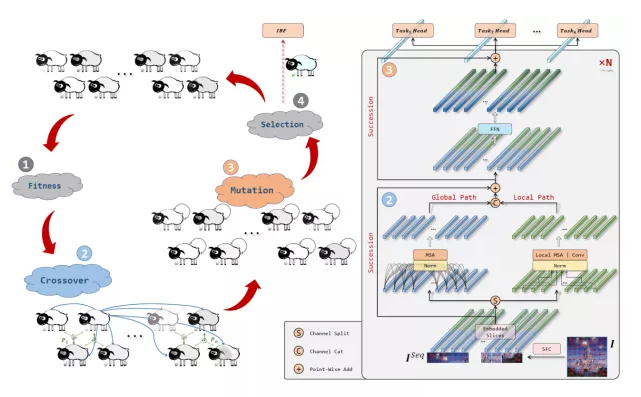
1. 局部路径:类比EA中的局部动态种群机制,我们在MSA中引入局部路径建模,可以增加模型效果的同时降低模型参数量。
2. 任务相关Head:我们使用Cross-Attention设计了Task-related Head,使得一个模型可以优雅地胜任多种任务,比如分类、蒸馏、无监督的拼图预测和角度预测等。使用时初始化任务相关token作为query,图像特征作为key和value,使用Cross Attention和MLP实现特征的聚合和提取。具体结构如图3所示:
3. 空间填充曲线:实现对高维的数据降维表征,以二维图像到一维序列化数据为例,我们可以使用已提出的索引曲线对图像按照预定义的结构顺序进行索引,如Sweep、Scan、Z-Order和Hilbert,如图4所示。同时我们也提出一种SweepInSweep的索引方式,其等价于已有的Patch Embedding过程,如图5所示。


实验:
1. ImageNet-1k分类实验:如表1所示,我们的模型相比于当前SOTA Transformer-Based方法具有更高的精度、更快的GPU和CPU运行速度以及更友好的推理显存占用,且模型越小时带来的提升越明显。在更高分辨率输入、更长时间训练和蒸馏等tricks的加持下,我们的模型能够获得更高的精度,比如EAT-Ti在仅5.7M的参数下可以取得76.9的Top-1结果。
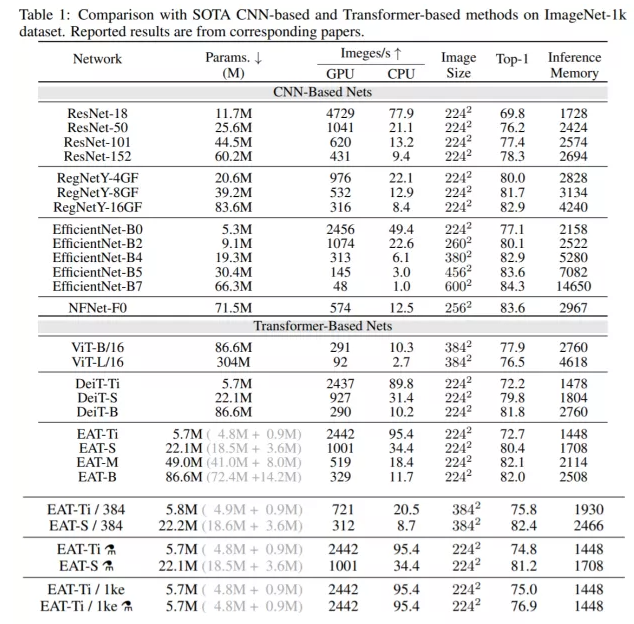
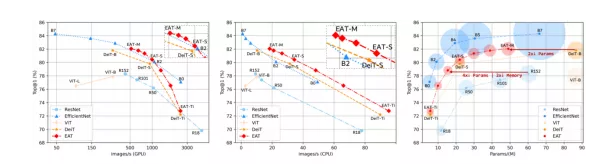
图6展示了不同方法在GPU速度、CPU速度、参数量、推理显存占用、Top-1精度指标上的直观对比,结果显示我们的方法具有更高的精度和效率。
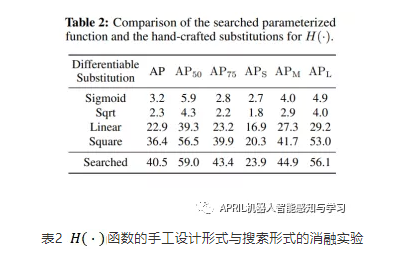
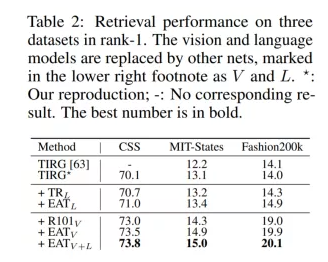
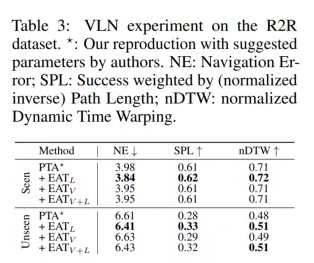
2. 我们在Text-based Image Retrieval和Vision Language Navigation上进行了多模态实验,如表2和表3所示,定量结果显示我们的方法在仅使用一个统一模型的情况下能够对已有的方法带来结果的提升。
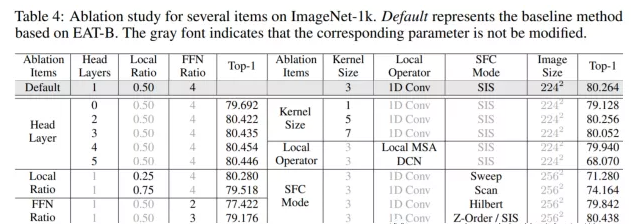
3. 我们在80.264的strong baseline对EAT做了剥离实验,结果表明我们提出的改进能够带来模型效果的提升。
4. 我们对训练好的模型进行可视化如图7所示,结果表明我们的方法能够很好地关注画面中的重要区域。

02 Searching Parameterized AP Loss for object detection(为目标检测搜索参数化平均准确率损失函数)
背景介绍:
损失函数(loss function)在基于深度学习的目标检测领域一直起着至关重要的作用。对于目标检测任务一般使用的则是一个同时考虑定位和分类子任务的评估指标:平均准确率(AP)。然而由于AP计算的不可导性,传统的目标检测网络对两个子任务采用分离的可导损失函数,这一不对齐问题导致了网络表现的退化。为了解决该问题,一些现有的工作人为地设计了一系列AP的替代损失函数,这一过程一般需要专业知识且结果通常仍是次优的。本工作中我们提出参数化平均准确率损失函数(Parameterized AP Loss),使用参数化损失函数替代AP计算中的不可导部分,将不同的AP近似方法统一到一个参数化函数族下,之后利用搜索算法搜索最优的参数形式。我们的贡献有以下几点:
1. 通过数学上推导AP计算并引入可导的参数化损失函数,提出的Parameterized AP Loss可以在一个统一的形式下表示大量的可能的AP近似,该近似式即可作为一个同时优化目标检测任务的定位子任务与分类子任务的损失函数。
2. 不同于手工设计AP损失函数或损失函数梯度的近似,我们的方法框架通过在一个目标检测网络训练的搜索任务上迭代优化,自动地搜索损失函数中参数化函数族需要的最优参数。
3. 基于不同的目标检测网络结构的实验证明,搜索到的Parameterized AP Loss的表现可以稳定地超过一系列现有的损失函数。
参数化平均准确率函数 Parameterized AP Loss:
通过数学上的推导,可以在假定定位准确(所有网络输出检测框已经与真值进行计算得到正负样本区分)的前提下,将平均准确率的计算写为:
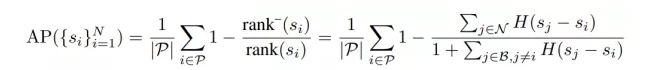

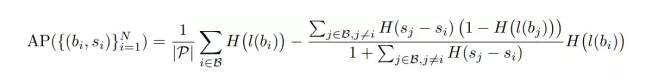

最优参数搜索过程:

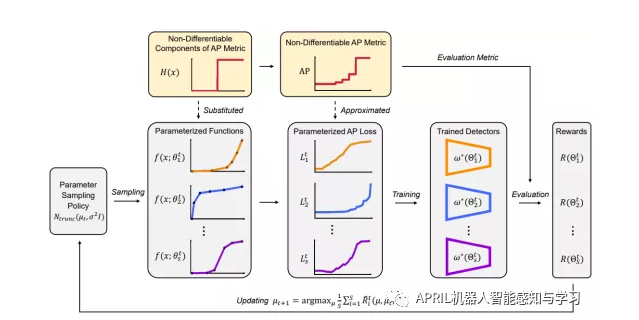
整个方法如图3所示,其核心在于用可导的参数化函数去替代AP计算中不可导的部分,并在一个数据规模小,训练周期短,但与目标检测网络完整训练周期相关性强的代理任务上测试每次采用的参数集的性能,之后用强化学习算法去迭代优化参数采样范围,以此保证搜索过程的有效和高效性,最终将采样到的最优参数组成的损失函数作为最后的参数化平均准确率损失函数。
实验:
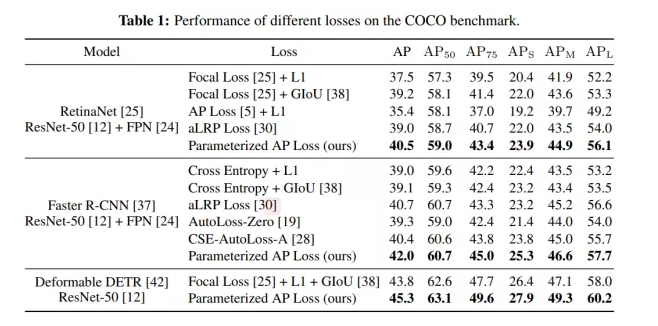
我们在mmdetection的框架上选用三个代表性的目标检测网络:一阶段检测器RetinaNet,两阶段检测器Faster R-CNN和Set prediction型检测器Deformable DETR,三个网络结构及选用的训练超参数等均保持一致,只替换训练时使用的损失函数。可以看到,我们提出的损失函数相比于过去一系列的人手工设计或搜索得到的损失函数有明显的性能提升