APRIL实验室2篇论文被ICCV 2021录用
国际计算机视觉大会(ICCV,International Conference on Computer Vision)由美国电气和电子工程师学会(IEEE,Institute of Electrical & Electronic Engineers)主办,与计算机视觉模式识别会议(CVPR)和欧洲计算机视觉会议(ECCV)并称计算机视觉方向的三大顶级会议。
计算机视觉是当前计算机科学研究的一个非常活跃的领域,该学科旨在为计算机和机器人开发出具有与人类水平相当的视觉能力。

ICCV每两年举办一届,其论文集代表了计算机视觉领域最新的发展方向和水平。要知道,ICCV 论文录用率非常低,也是三大顶会中公认级别最高的。在此恭喜APRIL实验室博士生黄田鑫和博士生刘丽娜论文被ICCV 2021录用!
01 RFNet : Recurrent Forward Network for Dense Point Cloud Completion(RFNet:前向递归稠密点云补全网络)
随着LiDAR,深度相机等3D传感器的快速发展,3D数据在计算机视觉和机器人技术中越来越受到关注。作为一种能够比2D图像更好地描述场景空间结构的数据形式,3D 点云已广泛应用于SLAM和目标检测等应用中。然而,由于分辨率和遮挡的限制,直接从传感器获取的点云往往是不完整且稀疏的。因此,从不完整的残缺模型中恢复完整的稠密模型是一项重要且具有挑战性的任务。
近年来,许多基于深度学习的网络模型已经在3D点云补全任务上取得了比较好的效果,但这些网络往往需要高维全局特征或多个局部特征来从输入中获取足够的形状信息,具有较大的参数量和资源消耗。除此之外,现有的工作往往基于encoder-decoder的自编码器框架,仅仅依靠损失函数约束输出模型,补全结果常常会丢失输入残缺点云中的一些细节。
针对这些问题,本文设计了一个基于轻量化的高效稠密点云补全框架。针对其他方法中参数量大,资源消耗高的问题,该框架在部分模块之间进行参数共享,每一级的输出模型和残缺模型混合作为下一级的输入模型,并用最后一级的输出作为最终的补全结果。在这一架构下,模型的参数量和资源消耗都得到了极大降低。
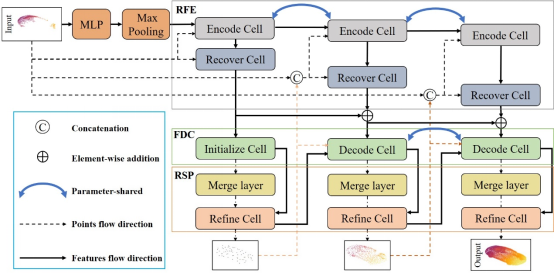
针对其他方法的输出模型会丢失输入残缺模型细节的问题,我们提出了一种可学习的模型融合策略来可微地融合残缺模型和补全结果,比较好地保留了原有模型的细节,避免失真。根据在ShapeNet和Kitti两个数据集上的测试,我们的方法能够在较小的时间消耗,最低的内存消耗,和最小的参数量下,达到最好的补全效果。

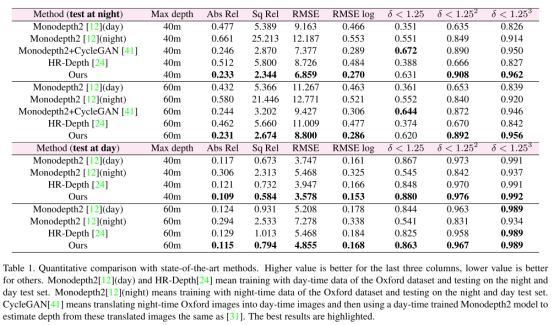
02 Self-supervised Monocular Depth Estimation for All Day Images using Domain Separation(域分离的全时段自监督单目深度估计)
近年来,基于 DCNN 的自监督深度估计方法取得了显着的成果。然而,这些方法中的大多数只能处理单一的白天或夜间的图像。由于昼夜图像之间的光照变化和较大的域差异,大多数方法对全时段图像的单目深度估计性能会下降。为了缓解这些限制,我们提出了一个域分离框架,用于全时段图像的自监督深度估计。我们的关键思想是将全时段信息分成两个互补的子空间来减轻深度估计中干扰项的影响:私有域和不变域;此外正交性和相似性损失用于分离有效和互补的特征。同时,利用重构损失来细化获得的补充信息(私有和不变信息)。

具体来说,为了减轻干扰项(光照等)的负面影响,我们将白天和夜间图像对的信息划分为两个互补的子空间:私有域和不变域。其中前者包含白天和夜间图像各自特有的信息(光照等),后者包含域不变的共享信息(纹理等),这些信息是进行深度估计的关键部分。同时,未配对的昼夜图像总是包含不一致的信息,这会干扰私有和不变特征的分离。因此,域分离网络以一对白天图像和对应的夜间图像(由 GAN 生成)作为输入,首先利用私有和不变特征提取器来提取私有(照明等)和不变特征(纹理等)。这些特征使用正交性和相似性损失进行约束,可以获得更有效的用于白天和夜间图像深度估计的特征。此外,在正交性损失中利用特征和Gram矩阵级别的约束来减轻域差异,从而可以获得更有效的域不变特征和细粒度深度图。然后,深度图和相应的 RGB 图像由具有重建和光度损失的解码器模块重建。我们的方法可以有效缓解低能见度和不均匀照明的问题,并为夜间图像的深度估计取得更有吸引力的结果。
实验结果表明,我们的方法在具有挑战性的 Oxford RobotCar 数据集上实现了全时段图像均提升的深度估计结果,证明了我们提出的方法的优越性。