APRIL实验室6篇论文被IROS 2021录用
IEEE/RSJ智能机器人与系统国际会议(IROS)是全球规模最大、影响力最强的机器人研究会议之一。IROS成立于1988年,每年举办一次,为国际机器人研究界提供了一个探讨智能机器人和智能机器科技前沿的国际论坛。
很荣幸,APRIL实验室有6篇论文被IROS 2021录用。
01
CLINS: Continuous-Time Trajectory Estimation for LiDAR-Inertial System
CLINS: 激光惯性系统的连续时间轨迹估计
近几年,SLAM 领域发展迅速,出现一系列开源方法,广泛应用于智能机器人、自动驾驶、AR\VR 等领域。多传感器融合因其互补性、鲁棒性被广泛研究与应用。多传感器融合按状态量的定义可分为离散型、连续型两大类。离散型方法较为通用也被研究最多,通常使用预积分技术将高频 IMU 数据转换为低频预积分量,与图像或激光特征数据融合,状态量一般与后两者频率相同;传统离散型建模方法存在一些缺陷:
1、异步、异频数据融合:不同传感器因测量时刻、测量频率不同而带来的融合困难;
2、高频外感受型数据融合:卷帘门相机、事件相机、激光传感器扫描式测量,若搭载这些传感器的平台有相对运动,则传感器测量数据存在运动畸变,会影响建图质量、状态估计精度。
上述几个难点可总结为离散位姿难以满足系统对高频位姿的需求,而连续型方法将轨迹建模为连续时间函数,支持查询任意时刻位姿、速度,自然而然地解决异步、异频、高频多传感器数据融合的问题。因此连续性建模方法近几年逐渐受到关注,如事件相机、激光、相机等多传感器融合系统。
在本论文中,我们提出了一种准确的连续时间轨迹估计框架,其能够有效地实现融合高频和异步传感器数据。我们将该框架应用于3D激光-惯性系统中进行评估。具体地,该方法采用连续时间轨迹估计的非刚性匹配方法,在点云匹配的同时考虑激光扫描的运动失真。此外,我们提出了一种二阶段的连续时间轨迹校正方法,高效、快速地完成回环修正。
相关算法近期将会开源,代码地址:https://github.com/april-zju/clins。

基于3D激光和 IMU 系统估计的连续轨迹,可方便地对高精度的 2D激光(Sight LMS-511)测量建图。
02
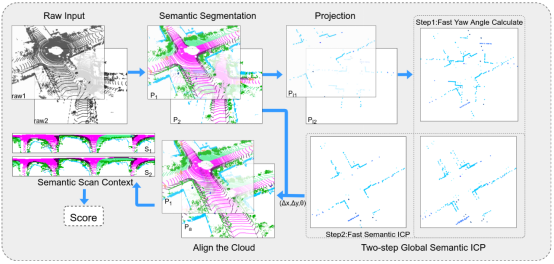
SSC: Semantic Scan Context for Large-Scale Place Recognition
语义扫描上下文:一种针对大范围场景的闭环检测方法
该论文针对低层次的信息难以对场景进行充分编码的问题,提出了一种新的基于语义的全局描述,通过语义信息的使用该方法可以实现对场景的有效编码;针对大部分闭环检测方法忽略闭环点云间平移导致检测精度下降的问题,提出了一种两阶段全局语义ICP算法,该方法可以在没有初始位姿的情况下计算闭环点云间的三自由度位姿(x,y, yaw),从而消除旋转和平移对识别的影响,同时为进一步修正位姿提供较好的初始值。
03
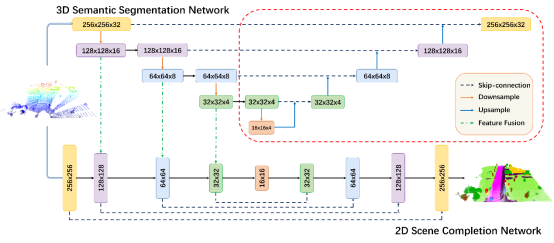
Semantic Segmentation-assisted Scene Completion for LiDAR Point Clouds
语义分割辅助的雷达点云场景补全
室外场景补全是 3D 场景理解中的一个具有挑战性的问题,在智能机器人和自动驾驶领域中都担任着重要的角色。由于 LiDAR 采集的稀疏性,三维场景补全和语义分割会更加复杂。由于语义特征可以为补全任务提供约束和语义先验,因此它们之间的关系值得探索。因此,我们提出了一个端到端的语义分割辅助场景补全网络,包括一个 2D 补全分支和一个 3D 语义分割分支。具体来说,网络以原始点云为输入,将来自语义分割分支的特征分层融合到补全分支以提供语义信息。通过同时采用BEV 表示和 3D 稀疏卷积,我们可以在提取有效特征的同时使用较少的操作。此外,分割分支的解码器部分作为辅助网络,可以在推理阶段丢弃以减轻计算负担。实验表明,我们的方法在 SemanticKITTI 数据集上以较低延迟实现了良好的性能。
04
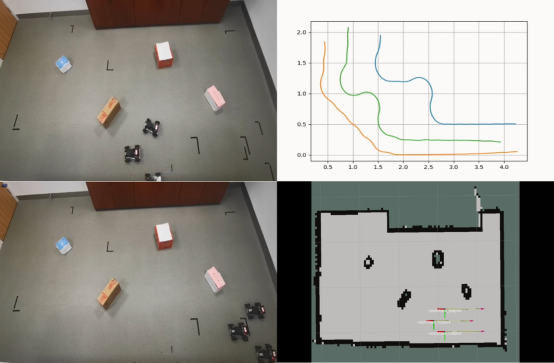
Moving Forward in Formation: A Decentralized Hierarchical Learning Approach to Multi-Agent Moving Together
在队列中前进:一种去中心化分层强化学习多智能体编队方法
多智能体寻路策略有很多潜在的实际应用,如移动仓库机器人。但是,以前的多智能体路径规划 (MAPF) 方法几乎不考虑队形的问题。此外,他们通常是集中执行的策略并需要整个全局的视野。其他去中心化部分可观察MAPF 的方法是强化学习 (RL) 方法。然而,这些 RL 方法在学习时遇到了困难,尤其是同时解决寻路和形成问题的时候。在这篇论文,我们提出了一种新颖的去中心化部分可观察使用层次结构分解的RL算法将多目标任务分解为不相关的任务。此外,我们的工作还计算一个理论权重使每个任务的奖励具有对最终 RL 值函数相等的影响。在模拟实验中,我们的方法优于其他端到端 RL 方法,并且我们的方法可以自然地扩展到大集中式规划方法无法处理的世界大小。此外,我们还在真实场景中部署并验证了我们的方法的有效性。
05
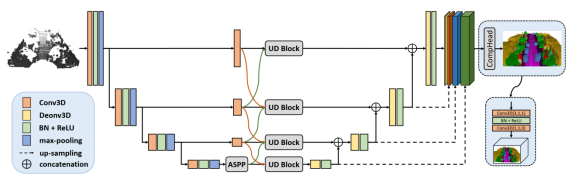
Up-to-Down Network: Fusing Multi-Scale Context for 3D Semantic Scene Completion
一种融合多尺度背景信息的3d语义场景补全网络
为了解决自动驾驶场景中点云数据的稀疏和目标遮挡等问题对后续场景理解带来的挑战,本文提出了一种快速的并且支持多分辨率输出的点云语义场景补全网络——UDNet。提出的UD block可以有效聚合多尺度背景信息来提高标签一致性。同时为了满足不同任务的需求,我们的方法可以实现多分辨率的语义场景补全任务。我们的方法在SemanticKITTI语义场景补全数据集中在场景补全任务中取得最好的效果,在多分辨率补全任务中也优于目前最好的方法。
06
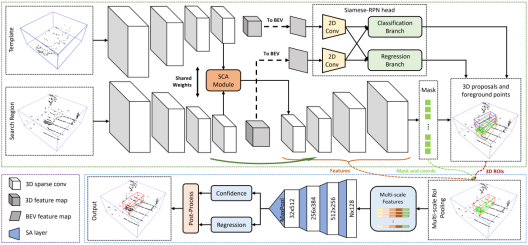
PointSiamRCNN: Target-Aware Voxel-based Siamese Tracker for Point Cloud
基于体素的点云目标感知孪生跟踪器
本文首次探索了基于体素的(Voxel-based)骨干网络在点云单目标跟踪中的性能。整个框架包括2个部分,候选框生成和优化。第一部分利用基于体素的孪生网络和孪生区域生成模块快速产生候选框,同时在搜索区域利用真值标签实现了前景点分割,进一步扩充语义信息。第二部分首先利用提出的池化模块聚合不同尺度的特征,然后利用PointNet++对每个候选框进行优化得到最后的跟踪结果。我们的方法在KITTI单目标跟踪任务中在3D跟踪方面达到了与当前最好的方法相比较的效果,在BEV跟踪方面优于当前最好的跟踪方法。