时间序列数据中的自监督学习:分类、进展与展望
自监督学习(Self-supervised Learning, SSL)在各种时间序列数据任务上取得了令人印象深刻的表现。SSL最突出的优点是减少了对标记数据的依赖。基于预训练和微调策略,即使少量的标记数据也能在时序分类、异常检测、预测任务上取得高性能。与许多已发表的关于计算机视觉和自然语言处理的自监督调查相比,目前仍然缺少针对时间序列数据SSL的全面调查。为了填补这一空白,我们在本文中回顾了当前最先进的时间序列数据SSL方法。为此,我们首先全面回顾与SSL和时间序列相关的现有调查,然后从基于生成、基于对比和基于对抗性三个角度进行总结,为现有时间序列SSL方法提供了新的分类方法。这些方法进一步被分为十个子类别,并对它们的关键概念、主要框架、优点和缺点进行了详细的回顾和讨论。为了方便时间序列 SSL 方法的实验和验证,我们还总结了时间序列预测、分类、异常检测和聚类任务中常用的数据集。最后,我们展示了时间序列SSL的未来方向。
论文链接:https://arxiv.org/abs/2306.10125。
一、引言
时间序列数据在现实世界的场景中非常常见,包括人类动作识别,工业故障诊断,智能建筑管理和医疗保健。基于时间序列分析的大多数任务的关键是提取信息丰富的特征。近年来,深度学习(Deep Learning, DL)在提取数据的隐藏模式和特征方面表现出了令人印象深刻的性能。通常,拥有足够多的标记数据是基于DL的特征提取模型的关键因素之一,这通常被称为监督学习。不幸的是,在某些实际场景中,这一要求很难达到,特别是针对以时间序列数据为分析对象的各类场景,获得高质量的标记数据是一个耗时的过程。作为一种替代方法,自监督学习(Self-supervised Learning, SSL)因其标签效率和泛化能力而受到越来越多的关注,因此,许多最新的时间序列建模方法已经遵循了这种学习范式。
SSL是无监督学习的一个子集,它利用代理任务从未标记的数据中获取监督信号。这些代理任务是模型为了从数据中学习表征而自定义或自生成的任务。SSL不需要额外的手动标记数据,因为监督信号来自数据本身。在精心设计的代理任务的帮助下,SSL最近在计算机视觉(Computer Vision, CV)和自然语言处理(Natural Language Processing, NPL)领域都取得了巨大成功,这使得将SSL扩展到时间序列数据变得非常吸引人。然而为CV/NLP设计的代理任务直接转移到时间序列数据上并非易事,并且在许多场景中行不通。在这里,我们认为将SSL应用于时间序列数据时会出现的一些独特的挑战。首先,时间序列数据往往有一些独特的特性,如季节性、趋势和频域信息。其次,SSL中常用的一些技术,如数据增强,需要为时间序列数据专门设计。第三,大多数时间序列数据包含多个维度,即多变量时间序列。然而,有用的信息通常只存在于少数维度中,这使得使用针对其他数据类型的SSL方法在时间序列中提取有用信息变得困难。
据我们所知,尚未有针对时间序列数据SSL的全面的回顾,虽然Eldele等人和Deldari等人提出的调查与我们的工作在某种程度上相似。然而,这两篇调查仅讨论了自监督对比学习的一小部分内容。此外,目前还缺乏基准时间序列数据集的总结和介绍,同时时间序列SSL的潜在研究方向也比较欠缺。基于以上问题,本文主要回顾了当前针对时间序列数据的最先进的SSL方法。我们首先总结了关于SSL和时间序列数据的最近综述,然后提出了一种基于生成,基于对比和基于对抗的分类方法。这个分类法与Liu等人提出的类似,但我们更专注于时间序列数据。对于基于生成的方法,我们描述了三个框架:基于自回归的预测(Autoregressive-based forecasting),基于自编码器的重构(Autoencoder-based reconstruction)和基于扩散模型的生成(Diffusion-based generation)。对于基于对比的方法,我们根据正样本和负样本的生成方式,将现有的工作划分为五个类别,包括采样对比(Sampling contrast),预测对比(Prediction contrast),增强对比(Augmentation contrast),原型对比(Prototype contrast)和专家知识对比(Expert knowledge contrast)。对于每一个类别,我们分析其见解和局限性。然后我们整理和总结了基于两个根据任务目标不同而划分的基于对抗的方法:时间序列生成/插补(Time series generation and imputation)和辅助表示增强(Auxiliary representation enhancement)。所提出的分类方法如图1所示。
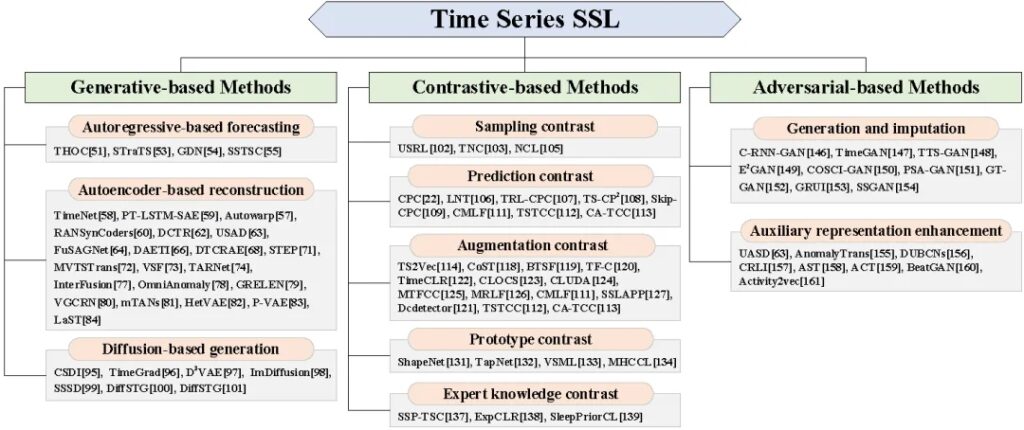
我们的主要贡献可以总结如下:
a. 新的分类方法。我们提供了新的分类法以及对时间序列 SSL 的详细且最新的总结。我们将现有方法分为十类,对于每一类,我们描述了基本框架、数学表达、详细比较以及优缺点。 据我们所知,这是第一篇全面、系统地回顾现有的时间序列数据 SSL 研究的工作。
b. 应用和数据集的收集。我们收集了有关时间序列SSL的资源,包括应用和数据集,并研究了相关数据来源、特征和对应的任务。
c. 丰富的未来方向。我们从应用和方法论的角度指出了这个领域的一些关键问题,分析了它们的原因和可能的解决方案,并讨论了时间序列SSL的未来研究方向。我们坚信,我们的努力将激发对时间序列SSL的进一步研究兴趣。
二、具体方法介绍
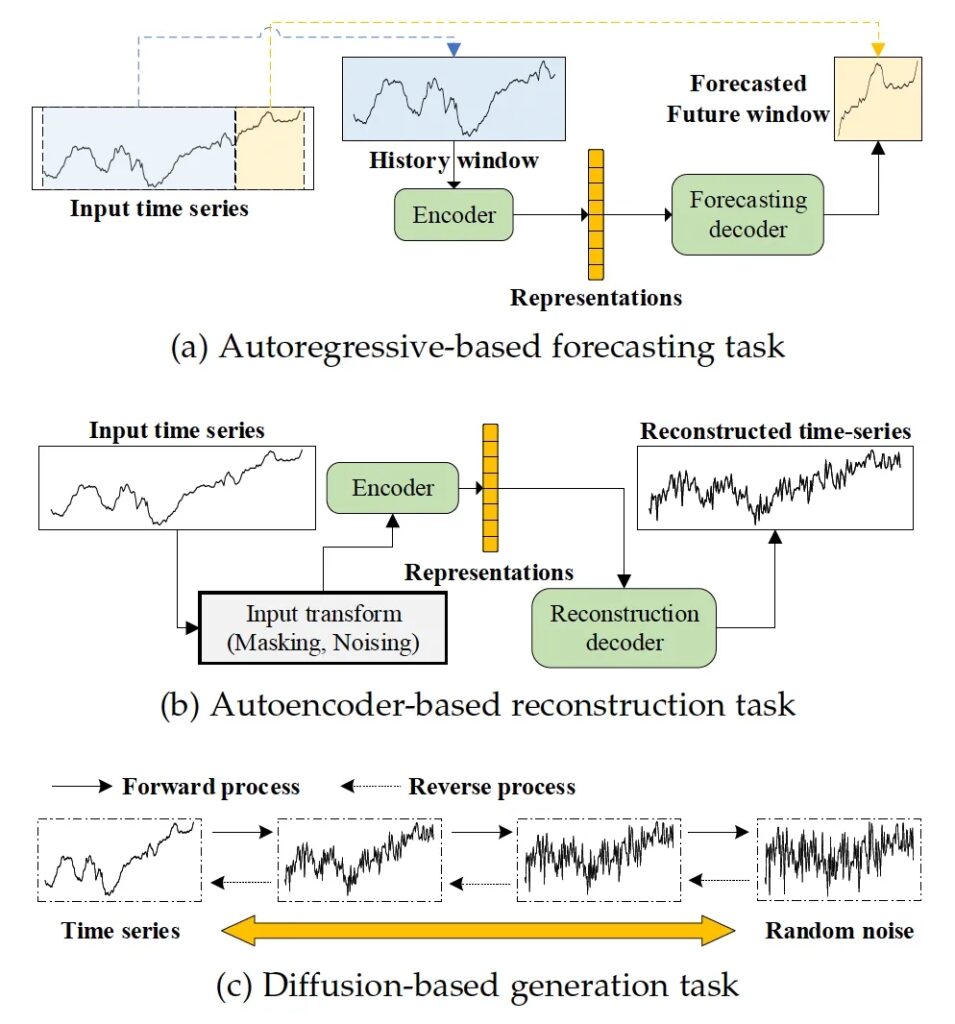
a. 基于生成的方法。在这一类别中,代理任务是根据给定的数据视图生成预期的数据。在时间序列建模的背景下,常用的代理任务包括使用过去的序列来预测未来的窗口或特定时间戳,使用编码器和解码器来重建输入,以及预测时间序列中被遮盖的部分。应该指出的是,基于自动编码器的重建任务也被视为无监督框架。在SSL的背景下,我们主要使用重建任务作为代理任务,最终目标是通过自动编码器模型获得输入的表征向量。基于生成的时间序列SSL的如图2所示。
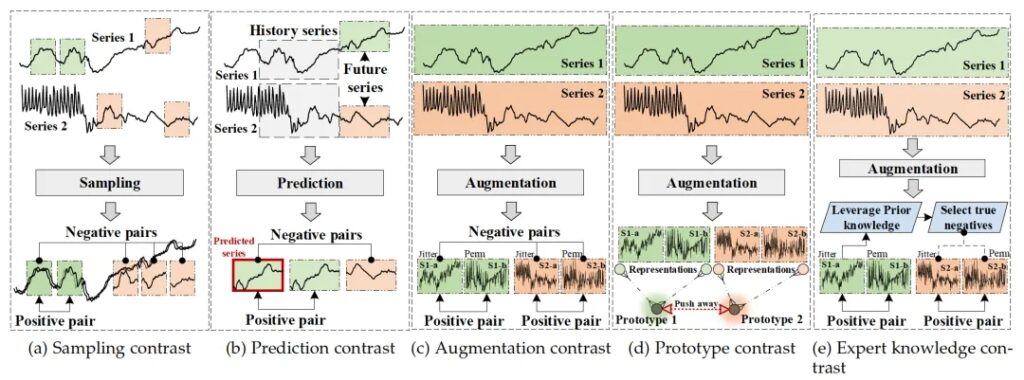
b. 基于对比的方法。对比学习是一种广泛使用的自监督学习策略,在计算机视觉和自然语言处理方面表现出强大的学习能力。与学习到真实标签的映射规则的判别模型和尝试重建输入的生成模型不同,基于对比的方法旨在通过对比正样本和负样本来学习数据表示。具体来说,正样本应该具有相似的表示,而负样本应该具有不同的表示。因此,正样本和负样本的选择对于基于对比的方法非常重要。我们根据正负样本的选择,对时间序列SSL中现有的基于对比的方法进行了梳理和总结,如图3所示。
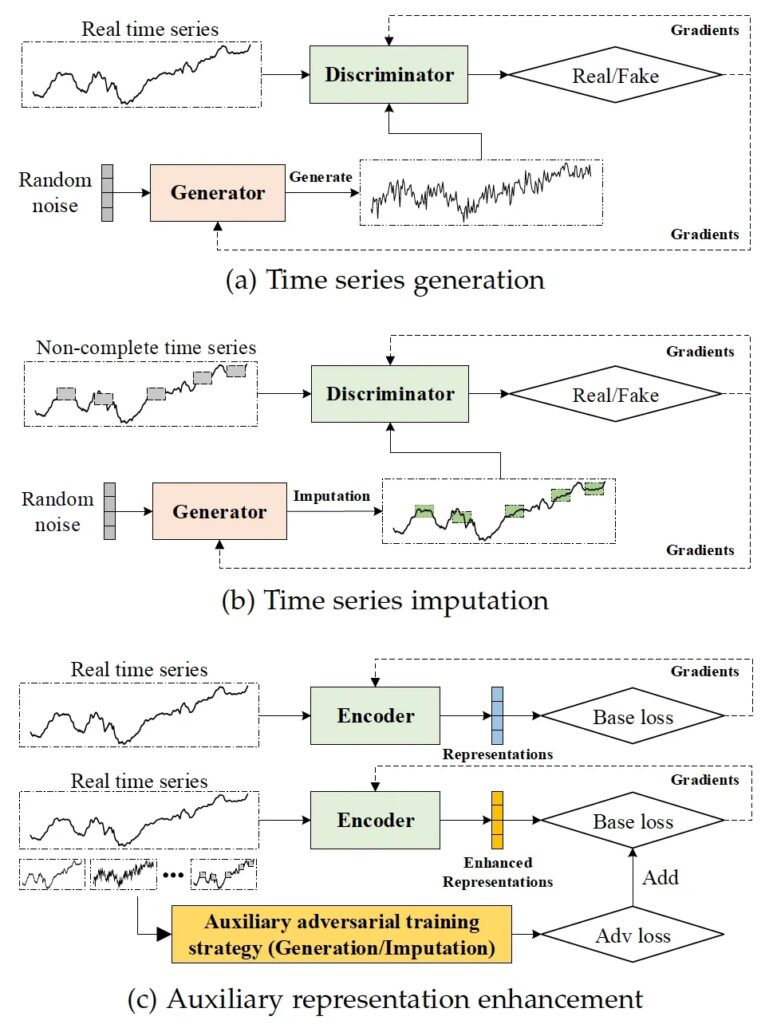
c. 基于对抗的方法。基于对抗的SSL利用生成对抗网络(Generative Adversarial Network, GAN)来构建代理任务。GAN 包含生成器和判别器。生成器负责生成与真实数据相似的合成数据,而判别器负责判断生成的数据是真实数据还是合成数据。因此,生成器的目标是最大化判别器的决策失败率,而判别器的目标是最小化其失败率。根据最终任务的任务目标,现有的基于对抗的SSL可以分为时间序列生成插补与辅助表示增强,如图4所示。
三、应用和数据集
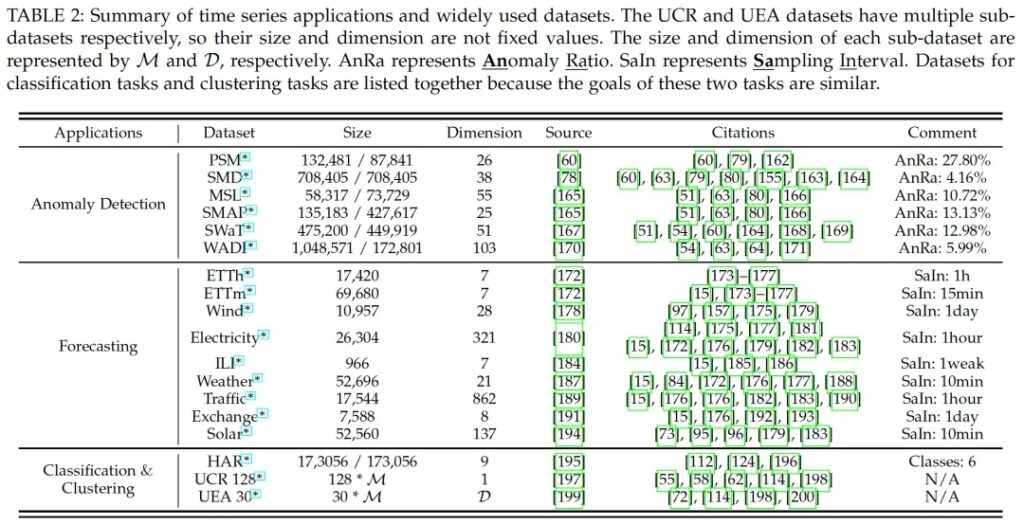
SSL在不同的时间序列任务中都有,如预测、分类、异常检测等。我们根据应用领域总结了最常用的数据集和代表性的参考文献。在本文中,我们收集了四个任务中广泛使用的数据集:异常检测、预测、分类和聚类。如表2所示,我们提供了有用的信息,包括数据集名称、维度、大小、来源、引用和有用的注释。分类任务和聚类任务的数据集一起列出,因为这两个任务的目标是一致的。
四、结论
我们重点介绍时间序列 SSL 方法并提供新的分类方法。根据现有的学习范式将已有方法分为三大类:基于生成、基于对比和基于对抗。此外,我们将所有方法分为十个详细的子类别:基于自回归的预测、基于自编码器的重建、基于扩散的生成、采样对比、预测对比、增强对比、原型对比、专家知识对比、生成和插补以及辅助表示增强。我们还提供有关应用和广泛使用的时间序列数据集的有用信息。最后总结了未来的多个方向。我们相信这篇综述填补了时间序列 SSL 的空白,并能够激发了人们对时间序列数据 SSL 的进一步研究兴趣。